
Hot News
O conceito de compressibilidade como sinal de qualidade não é amplamente conhecido, mas os SEOs devem estar cientes disso. Os mecanismos de pesquisa podem usar a compressibilidade de páginas da web para identificar páginas duplicadas, páginas de entrada com conteúdo semelhante e páginas com palavras-chave repetitivas, tornando-o um conhecimento útil para SEO.
Embora o artigo de pesquisa a seguir demonstre um uso bem-sucedido de recursos na página para detecção de spam, a falta deliberada de transparência por parte dos mecanismos de pesquisa torna difícil dizer com certeza se os mecanismos de pesquisa estão aplicando esta ou técnicas semelhantes.
O que é compressibilidade?
Na computação, compressibilidade refere-se a quanto um arquivo (dados) pode ser reduzido em tamanho, mantendo informações essenciais, normalmente para maximizar o espaço de armazenamento ou para permitir que mais dados sejam transmitidos pela Internet.
TL/DR de compressão
A compactação substitui palavras e frases repetidas por referências mais curtas, reduzindo o tamanho do arquivo em margens significativas. Os mecanismos de pesquisa normalmente compactam páginas da web indexadas para maximizar o espaço de armazenamento, reduzir a largura de banda e melhorar a velocidade de recuperação, entre outros motivos.
Esta é uma explicação simplificada de como funciona a compactação:
- Identificar padrões:
Um algoritmo de compressão verifica o texto para encontrar palavras, padrões e frases repetidas - Códigos mais curtos ocupam menos espaço:
Os códigos e símbolos utilizam menos espaço de armazenamento do que as palavras e frases originais, o que resulta em um tamanho de arquivo menor. - Referências mais curtas usam menos bits:
O “código” que simboliza essencialmente as palavras e frases substituídas utiliza menos dados do que os originais.
Um efeito bônus do uso da compactação é que ela também pode ser usada para identificar páginas duplicadas, páginas de entrada com conteúdo semelhante e páginas com palavras-chave repetitivas.
Artigo de pesquisa sobre detecção de spam
Este artigo de pesquisa é significativo porque foi de autoria de renomados cientistas da computação conhecidos por avanços em IA, computação distribuída, recuperação de informações e outros campos.
Marc Najork
Um dos coautores do artigo de pesquisa é Marc Najork, um proeminente cientista pesquisador que atualmente detém o título de Distinguished Research Scientist no Google DeepMind. Ele é coautor dos artigos do TW-BERT, contribuiu com pesquisas para aumentar a precisão do uso de feedback implícito do usuário, como cliques, e trabalhou na criação de recuperação aprimorada de informações baseada em IA (DSI++: Atualizando a memória do transformador com novos documentos), entre muitos outros avanços importantes na recuperação de informações.
Dennis Fetterly
Outro dos coautores é Dennis Fetterly, atualmente engenheiro de software no Google. Ele está listado como co-inventor em uma patente de um algoritmo de classificação que usa links e é conhecido por suas pesquisas em computação distribuída e recuperação de informações.
Esses são apenas dois dos ilustres pesquisadores listados como coautores do artigo de pesquisa da Microsoft de 2006 sobre a identificação de spam por meio de recursos de conteúdo na página. Entre as diversas características do conteúdo da página que o artigo de pesquisa analisa está a compressibilidade, que eles descobriram que pode ser usada como um classificador para indicar que uma página da web contém spam.
Detectando páginas da Web com spam por meio de análise de conteúdo
Embora o artigo de pesquisa tenha sido escrito em 2006, suas descobertas permanecem relevantes até hoje.
Naquela época, como agora, as pessoas tentaram classificar centenas ou milhares de páginas da web baseadas em localização que eram essencialmente conteúdo duplicado, exceto nomes de cidades, regiões ou estados. Naquela época, como agora, os SEOs frequentemente criavam páginas da web para mecanismos de pesquisa repetindo excessivamente palavras-chave em títulos, meta descrições, cabeçalhos, texto âncora interno e no conteúdo para melhorar as classificações.
A seção 4.6 do artigo de pesquisa explica:
“Alguns motores de busca dão peso maior às páginas que contêm as palavras-chave da consulta várias vezes. Por exemplo, para um determinado termo de consulta, uma página que o contém dez vezes pode ter uma classificação mais elevada do que uma página que o contém apenas uma vez. Para tirar proveito de tais mecanismos, algumas páginas de spam replicam seu conteúdo várias vezes na tentativa de obter uma classificação mais elevada.”
O artigo de pesquisa explica que os mecanismos de pesquisa compactam páginas da web e usam a versão compactada para fazer referência à página da web original. Eles observam que quantidades excessivas de palavras redundantes resultam em um nível mais alto de compressibilidade. Então eles começaram a testar se havia uma correlação entre um alto nível de compressibilidade e spam.
Eles escrevem:
“Nossa abordagem nesta seção para localizar conteúdo redundante em uma página é compactar a página; para economizar espaço e tempo em disco, os mecanismos de pesquisa geralmente compactam as páginas da web após indexá-las, mas antes de adicioná-las ao cache de páginas.
…Medimos a redundância das páginas da web pela taxa de compactação, o tamanho da página descompactada dividido pelo tamanho da página compactada. Usamos GZIP… para compactar páginas, um algoritmo de compactação rápido e eficaz.”
Alta compressibilidade se correlaciona com spam
Os resultados da pesquisa mostraram que páginas da web com taxa de compactação de pelo menos 4,0 tendem a ser páginas da web de baixa qualidade, spam. No entanto, as taxas mais altas de compressibilidade tornaram-se menos consistentes porque havia menos pontos de dados, dificultando a interpretação.
Figura 9: Prevalência de spam em relação à compressibilidade da página.
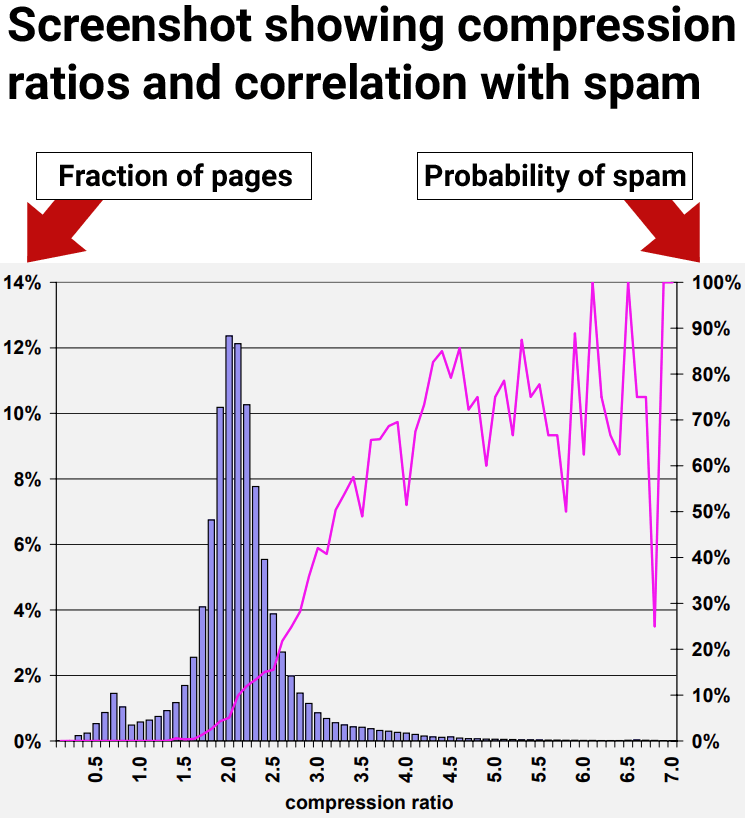
Os pesquisadores concluíram:
“70% de todas as páginas amostradas com uma taxa de compactação de pelo menos 4,0 foram consideradas spam.”
Mas eles também descobriram que o uso da taxa de compactação por si só ainda resultava em falsos positivos, onde páginas que não eram spam eram identificadas incorretamente como spam:
“A heurística da taxa de compressão descrita na Seção 4.6 teve o melhor desempenho, identificando corretamente 660 (27,9%) das páginas de spam em nossa coleção, enquanto identificou incorretamente 2.068 (12,0%) de todas as páginas julgadas.
Usando todos os recursos mencionados acima, a precisão da classificação após o processo de validação cruzada de dez vezes é encorajadora:
95,4% das nossas páginas julgadas foram classificadas corretamente, enquanto 4,6% foram classificadas incorretamente.
Mais especificamente, para a classe de spam 1.940 das 2.364 páginas foram classificadas corretamente. Para a classe não-spam, 14.440 das 14.804 páginas foram classificadas corretamente. Consequentemente, 788 páginas foram classificadas incorretamente.”
A próxima seção descreve uma descoberta interessante sobre como aumentar a precisão do uso de sinais na página para identificar spam.
🔥 Dica do Técnico: Encontra gadgets e peças de reparação a preços incríveis.
Ver Ofertas Flash ⚡*Ao comprar através deste link, apoias o site sem custo extra.
Insights sobre classificações de qualidade
O artigo de pesquisa examinou vários sinais na página, incluindo compressibilidade. Eles descobriram que cada sinal individual (classificador) era capaz de encontrar algum spam, mas que depender de qualquer sinal por si só resultava na sinalização de páginas não-spam como spam, que são comumente chamadas de falso positivo.
Os pesquisadores fizeram uma descoberta importante que todos os interessados em SEO deveriam saber: o uso de vários classificadores aumentou a precisão da detecção de spam e diminuiu a probabilidade de falsos positivos. Igualmente importante, o sinal de compressibilidade identifica apenas um tipo de spam, mas não toda a gama de spam.
A conclusão é que a compressibilidade é uma boa maneira de identificar um tipo de spam, mas existem outros tipos de spam que não são detectados com esse sinal. Outros tipos de spam não foram detectados com o sinal de compressibilidade.
Esta é a parte que todo SEO e editor deve estar ciente:
“Na seção anterior, apresentamos uma série de heurísticas para avaliar páginas de spam. Ou seja, medimos diversas características de páginas da web e encontramos intervalos dessas características que se correlacionavam com o fato de uma página ser spam. No entanto, quando usada individualmente, nenhuma técnica revela a maior parte do spam em nosso conjunto de dados sem sinalizar muitas páginas que não são spam como spam.
Por exemplo, considerando a heurística da taxa de compressão descrita na Seção 4.6, um dos nossos métodos mais promissores, a probabilidade média de spam para taxas de 4,2 e superiores é de 72%. Mas apenas cerca de 1,5% de todas as páginas se enquadram nessa faixa. Este número está muito abaixo dos 13,8% de páginas de spam que identificamos em nosso conjunto de dados.”
Portanto, embora a compressibilidade fosse um dos melhores sinais para identificar spam, ainda não foi possível descobrir toda a gama de spam no conjunto de dados que os pesquisadores usaram para testar os sinais.
Combinando Vários Sinais
Os resultados acima indicaram que sinais individuais de baixa qualidade são menos precisos. Então eles testaram usando vários sinais. O que eles descobriram foi que a combinação de vários sinais na página para detectar spam resultou em uma melhor taxa de precisão, com menos páginas classificadas erroneamente como spam.
Os pesquisadores explicaram que testaram o uso de vários sinais:
“Uma forma de combinar nossos métodos heurísticos é ver o problema de detecção de spam como um problema de classificação. Neste caso, queremos criar um modelo de classificação (ou classificador) que, dada uma página web, utilizará os recursos da página em conjunto para (corretamente, esperamos) classificá-la em uma de duas classes: spam e não spam. .”
Estas são as conclusões sobre o uso de vários sinais:
“Estudamos vários aspectos do spam baseado em conteúdo na web usando um conjunto de dados reais do rastreador MSNSearch. Apresentamos vários métodos heurísticos para detectar spam baseado em conteúdo. Alguns de nossos métodos de detecção de spam são mais eficazes que outros; no entanto, quando usados isoladamente, nossos métodos podem não identificar todas as páginas de spam. Por esse motivo, combinamos nossos métodos de detecção de spam para criar um classificador C4.5 altamente preciso. Nosso classificador pode identificar corretamente 86,2% de todas as páginas de spam, enquanto sinaliza muito poucas páginas legítimas como spam.”
Informações principais:
A identificação incorreta de “muito poucas páginas legítimas como spam” foi um avanço significativo. O insight importante que todos os envolvidos com SEO devem tirar disso é que um sinal por si só pode resultar em falsos positivos. O uso de vários sinais aumenta a precisão.
O que isso significa é que os testes de SEO de classificação isolada ou sinais de qualidade não produzirão resultados confiáveis para a tomada de decisões estratégicas ou de negócios.
Conclusões
Não sabemos ao certo se a compressibilidade é usada nos motores de busca, mas é um sinal fácil de usar que, combinado com outros, pode ser usado para capturar tipos simples de spam, como milhares de páginas de entrada com nomes de cidades com conteúdo semelhante. No entanto, mesmo que os motores de busca não utilizem este sinal, isso mostra como é fácil detectar esse tipo de manipulação dos motores de busca e que é algo que os motores de busca são capazes de lidar hoje.
Aqui estão os pontos principais deste artigo que você deve ter em mente:
- As páginas de entrada com conteúdo duplicado são fáceis de detectar porque são compactadas em uma proporção maior do que as páginas normais da web.
- Grupos de páginas da web com taxa de compactação acima de 4,0 eram predominantemente spam.
- Sinais de qualidade negativa usados por si só para capturar spam podem levar a falsos positivos.
- Neste teste específico, eles descobriram que os sinais de qualidade negativa na página detectam apenas tipos específicos de spam.
- Quando usado sozinho, o sinal de compressibilidade captura apenas spam do tipo redundância, não consegue detectar outras formas de spam e leva a falsos positivos.
- Combinar sinais de qualidade melhora a precisão da detecção de spam e reduz falsos positivos.
- Os mecanismos de pesquisa hoje têm maior precisão na detecção de spam com o uso de IA como o Spam Brain.
Leia o artigo de pesquisa, cujo link está na página do Google Scholar de Marc Najork:
Detectando páginas de spam por meio de análise de conteúdo
Imagem em destaque por Shutterstock/pathdoc
Siga-nos nas redes sociais:
Hotnews.pt |
Facebook |
Instagram |
Telegram
#hotnews #noticias #tecnologia #AtualizaçõesDiárias #SigaHotnews #FiquePorDentro #ÚltimasNotícias #InformaçãoAtual