
Se você é um profissional de SEO ou profissional de marketing do dedo que está lendo leste item, pode ter maduro IA e chatbots em seu trabalho quotidiano.
Mas a questão é: porquê você pode aproveitar ao supremo a IA além de usar uma interface de usuário de chatbot?
Para isso, você precisa de um conhecimento profundo de porquê funcionam os grandes modelos de linguagem (LLMs) e aprender o nível obrigatório de codificação. E sim, a codificação é absolutamente necessária para ter sucesso porquê profissional de SEO hoje em dia.
Leste é o primeiro de uma série de artigos que visam aprimorar suas habilidades para que você possa inaugurar a usar LLMs para dimensionar suas tarefas de SEO. Acreditamos que no porvir esta habilidade será necessária para o sucesso.
Precisamos inaugurar do obrigatório. Ele incluirá informações essenciais, portanto, posteriormente nesta série, você poderá usar LLMs para dimensionar seus esforços de SEO ou marketing para as tarefas mais tediosas.
Ao contrário de outros artigos semelhantes que você leu, começaremos cá pelo término. O vídeo inferior ilustra o que você poderá fazer em seguida ler todos os artigos da série sobre porquê usar LLMs para SEO.
Nossa equipe usa essa utensílio para agilizar a vinculação interna, mantendo a supervisão humana.
Você gostou? Isso é o que você mesmo poderá edificar muito em breve.
Agora, vamos inaugurar com o obrigatório e equipá-lo com o conhecimento prévio necessário em LLMs.
O que são vetores?
Em matemática, vetores são objetos descritos por uma lista ordenada de números (componentes) correspondentes às coordenadas no espaço vetorial.
Um exemplo simples de vetor é um vetor no espaço bidimensional, que é representado por (x,y) coordenadas conforme ilustrado inferior.
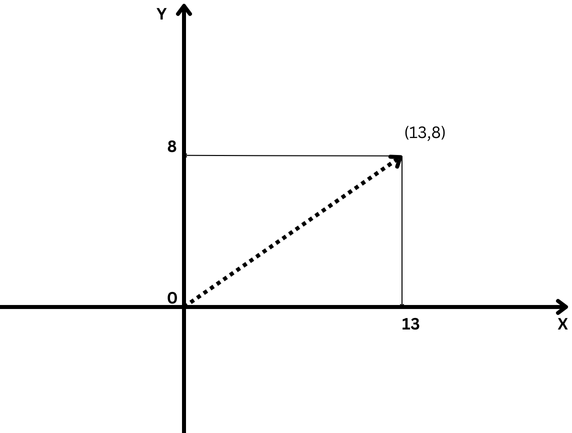 Modelo de vetor bidimensional com coordenadas x=13 e y=8 notadas porquê (13,8)
Modelo de vetor bidimensional com coordenadas x=13 e y=8 notadas porquê (13,8)Neste caso, a coordenada x=13 representa o comprimento da projeção do vetor no eixo X, e y=8 representa o comprimento da projeção do vetor no eixo Y.
Vetores definidos com coordenadas têm um comprimento, que é chamado de magnitude de um vetor ou norma. Para o nosso caso simplificado bidimensional, é calculado pela fórmula:
No entanto, os matemáticos foram em frente e definiram vetores com um número facultativo de coordenadas abstratas (X1, X2, X3… Xn), que é chamado de vetor “N-dimensional”.
No caso de um vetor no espaço tridimensional, seriam três números (x,y,z), que ainda podemos interpretar e compreender, mas qualquer coisa supra disso está fora da nossa imaginação, e tudo se torna um noção abstrato.
E é cá que os embeddings LLM entram em jogo.
O que é incorporação de texto?
Os embeddings de texto são um subconjunto de embeddings LLM, que são vetores abstratos de subida dimensão que representam texto que capturam contextos semânticos e relacionamentos entre palavras.
No jargão LLM, “palavras” são chamadas de tokens de dados, sendo cada vocábulo um token. Mais abstratamente, os embeddings são representações numéricas desses tokens, codificando relacionamentos entre quaisquer tokens de dados (unidades de dados), onde um token de dados pode ser uma imagem, gravação de som, texto ou quadro de vídeo.
Para calcular o quão próximas as palavras são semanticamente, precisamos convertê-las em números. Assim porquê você subtrai números (por exemplo, 10-6=4) e pode expressar que a intervalo entre 10 e 6 é de 4 pontos, é provável subtrair vetores e calcular quão próximos os dois vetores estão.
Assim, compreender as distâncias vetoriais é importante para compreender porquê funcionam os LLMs.
Existem diferentes maneiras de medir a proximidade dos vetores:
- Intervalo euclidiana.
- Semelhança ou intervalo de cosseno.
- Semelhança de Jaccard.
- Intervalo de Manhattan.
Cada um tem seus próprios casos de uso, mas discutiremos somente cossenos e distâncias euclidianas comumente usadas.
Qual é a similaridade do cosseno?
Mede o cosseno do ângulo entre dois vetores, ou seja, quão próximos esses dois vetores estão alinhados um com o outro.
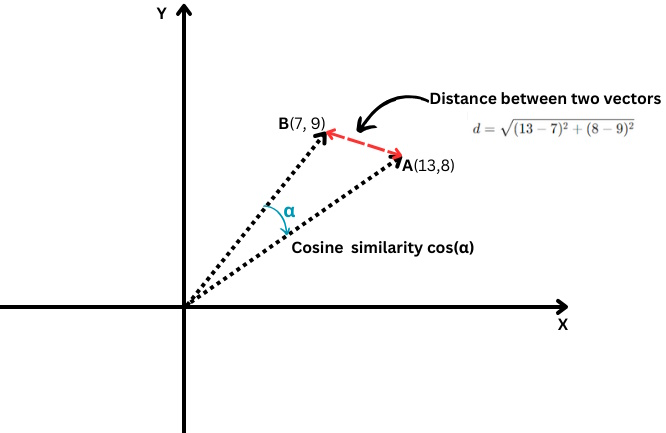 Intervalo euclidiana vs. similaridade de cosseno
Intervalo euclidiana vs. similaridade de cossenoÉ definido da seguinte forma:
Onde o resultado escalar de dois vetores é dividido pelo resultado de suas magnitudes, também conhecidos porquê comprimentos.
Seus valores variam de -1, que significa completamente oposto, a 1, que significa idêntico. Um valor ‘0’ significa que os vetores são perpendiculares.
Em termos de incorporações de texto, é improvável depreender o valor exato de similaridade de cosseno de -1, mas cá estão exemplos de textos com 0 ou 1 semelhança de cosseno.
Similaridade de cosseno = 1 (idêntico)
- “As 10 principais joias escondidas para viajantes individuais em São Francisco”
- “As 10 principais joias escondidas para viajantes individuais em São Francisco”
Esses textos são idênticos, portanto seus encaixes seriam os mesmos, resultando em uma similaridade de cosseno de 1.
Similaridade de cosseno = 0 (perpendicular, o que significa não relacionado)
- “Mecânica quântica”
- “Eu adoro dia pluviátil”
Esses textos são totalmente não relacionados, resultando em uma similaridade de cosseno de 0 entre seus embeddings de BERT.
No entanto, se você executar o padrão de incorporação ‘text-embedding-preview-0409’ do Google Vertex AI, obterá 0,3. Com os modelos ‘text-embedding-3-large’ do OpenAi, você obterá 0,017.
(Reparo: aprenderemos detalhadamente nos próximos capítulos a prática de embeddings usando Python e Jupyter).

Padrão text-‘embedding-preview-0409′ do Vertex Ai
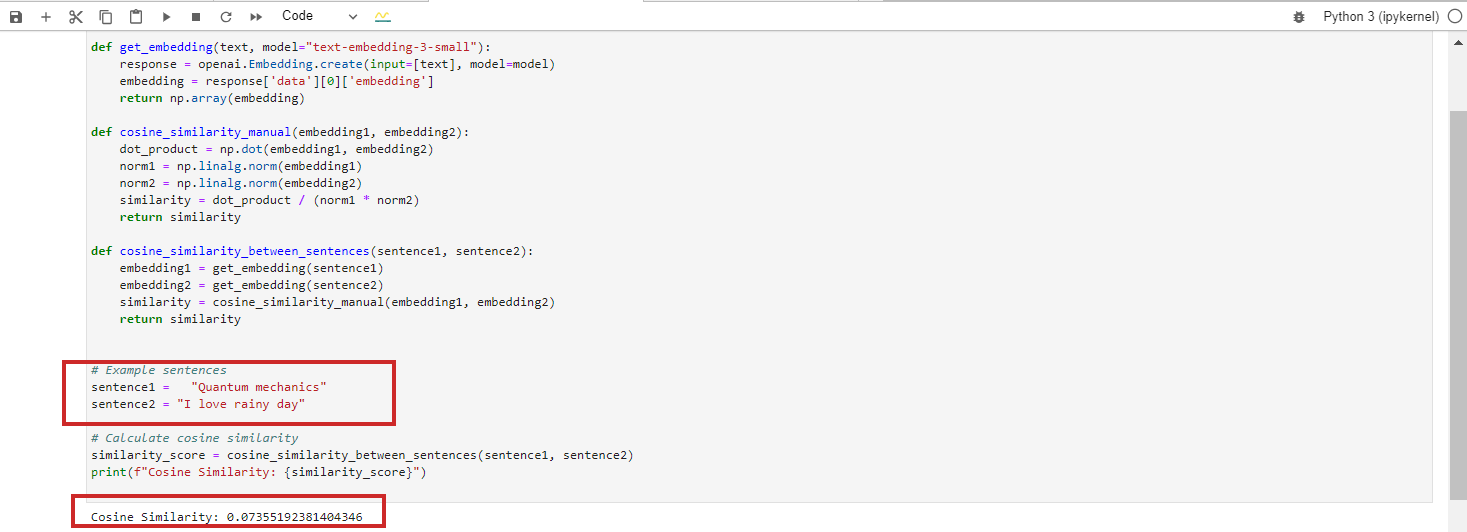
Padrão ‘text-embedding-3-small’ do OpenAi
Estamos ignorando o caso com similaridade de cosseno = -1 porque é altamente improvável que isso aconteça.
Se você tentar obter similaridade de cosseno para texto com significados opostos, porquê “paixão” versus “ódio” ou “o projeto bem-sucedido” versus “o projeto fracassado”, obterá similaridade de cosseno de 0,5-0,6 com o ‘texto- padrão de incorporação-preview-0409’.
É porque as palavras “paixão” e “ódio” aparecem frequentemente em contextos semelhantes relacionados com emoções, e “sucesso” e “fracasso” estão ambos relacionados com os resultados do projecto. Os contextos em que são utilizados podem sobrepor-se significativamente nos dados de formação.
A similaridade de cossenos pode ser usada para as seguintes tarefas de SEO:
- Classificação.
- Ajuntamento de palavras-chave.
- Implementando redirecionamentos.
- Vinculação interna.
- Detecção de teor geminado.
- Recomendação de teor.
- Estudo da concorrência.
A similaridade de cossenos concentra-se na direção dos vetores (o ângulo entre eles) e não em sua magnitude (comprimento). Uma vez que resultado, ele pode tomar a semelhança semiologia e instaurar o quão próximos dois pedaços de teor se alinham, mesmo que um seja muito mais longo ou use mais palavras que o outro.
Reprofundar profundamente e explorar cada um deles será o objetivo dos próximos artigos que publicaremos.
Qual é a intervalo euclidiana?
Caso você tenha dois vetores A(X1,Y1) e B(X2,Y2), a intervalo euclidiana é calculada pela seguinte fórmula:
É porquê usar uma régua para medir a intervalo entre dois pontos (a traço vermelha no gráfico supra).
A intervalo euclidiana pode ser usada para as seguintes tarefas de SEO:
- Avaliando a densidade de palavras-chave no teor.
- Encontrar teor geminado com estrutura semelhante.
- Analisando a distribuição do texto âncora.
- Ajuntamento de palavras-chave.
Cá está um exemplo de cômputo de intervalo euclidiana com valor de 0,08, quase próximo de 0, para teor geminado onde os parágrafos são somente trocados – o que significa que a intervalo é 0, ou seja, o teor que comparamos é o mesmo.
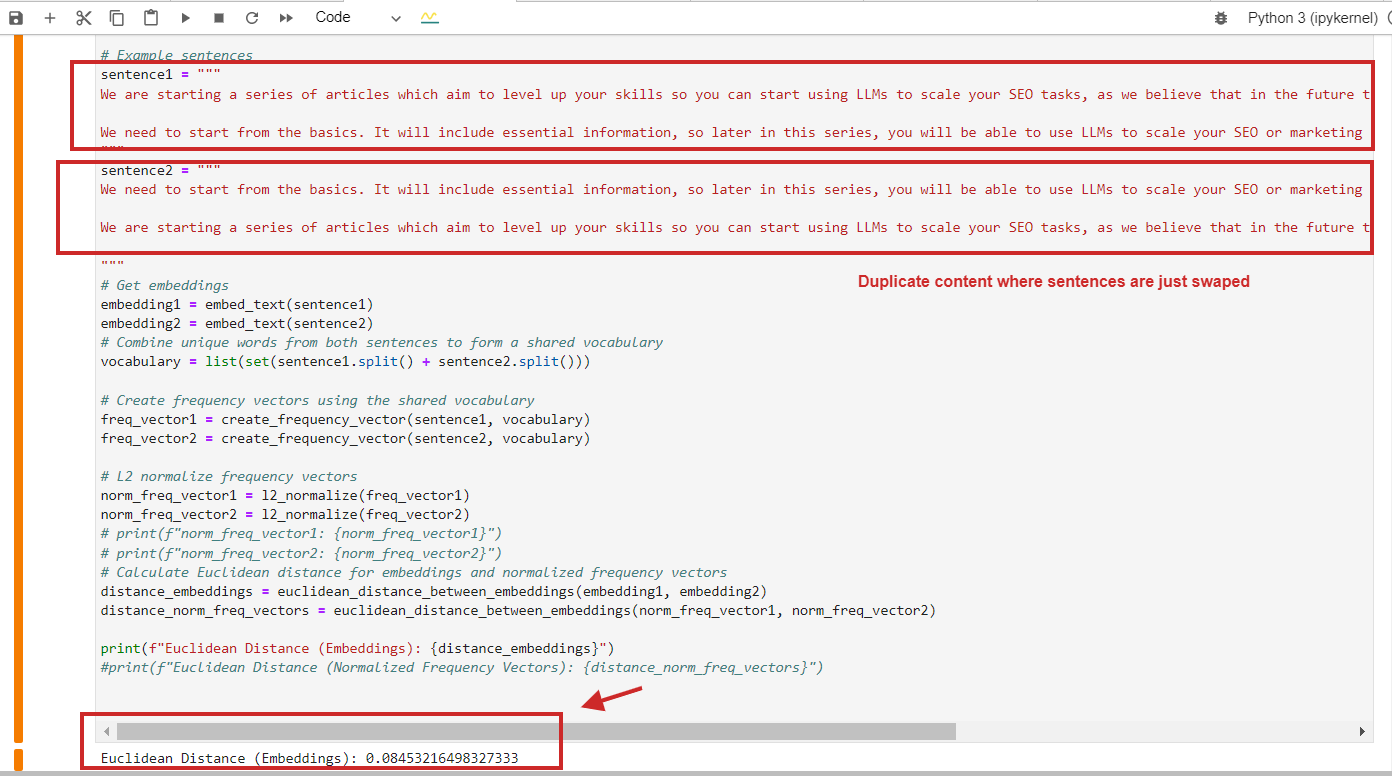 Exemplo de cômputo de intervalo euclidiana de teor geminado
Exemplo de cômputo de intervalo euclidiana de teor geminadoSimples, você pode usar a similaridade de cosseno e detectará teor geminado com similaridade de cosseno 0,9 em 1 (quase idêntico).
Cá está um ponto-chave a lembrar: você não deve encarregar somente na similaridade de cossenos, mas também usar outros métodos, já que o item de pesquisa da Netflix sugere que o uso da similaridade de cossenos pode levar a “semelhanças” sem sentido.
Mostramos que a similaridade de cosseno dos embeddings aprendidos pode de indumentária produzir resultados arbitrários. Descobrimos que a razão subjacente não é a semelhança de cossenos em si, mas o facto de os embeddings aprendidos terem um proporção de liberdade que pode gerar semelhanças arbitrárias de cossenos.
Uma vez que profissional de SEO, você não precisa ser capaz de compreender totalmente esse item, mas lembre-se de que pesquisas mostram que outros métodos de intervalo, porquê o euclidiano, devem ser considerados com base nas necessidades do projeto e no resultado obtido para reduzir falsos resultados. resultados positivos.
O que é normalização L2?
A normalização L2 é uma transformação matemática aplicada a vetores para torná-los vetores unitários com comprimento 1.
Para explicar em termos simples, digamos que Bob e Alice caminharam uma longa intervalo. Agora, queremos confrontar suas direções. Seguiram caminhos semelhantes ou seguiram direções completamente diferentes?
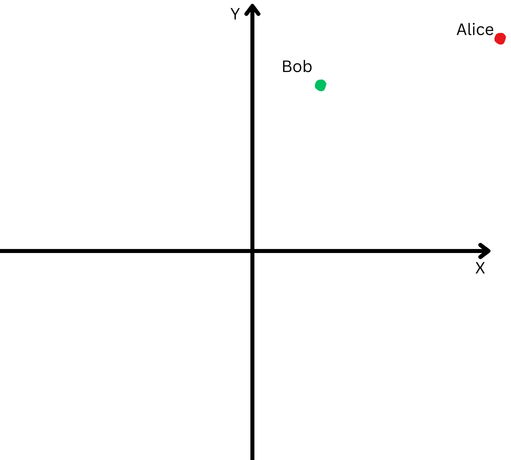 “Alice” é representada por um ponto vermelho no quadrante superior recta e “Bob” é representado por um ponto virente.
“Alice” é representada por um ponto vermelho no quadrante superior recta e “Bob” é representado por um ponto virente.Porém, porquê estão longe de sua origem, teremos dificuldade em medir o ângulo entre seus caminhos porque foram longe demais.
Por outro lado, não podemos declarar que se estiverem distantes um do outro, isso significa que seus caminhos são diferentes.
A normalização L2 é porquê trazer Alice e Bob de volta à mesma intervalo mais próxima do ponto inicial, digamos, um pé da origem, para facilitar a mensuração do ângulo entre seus caminhos.
Agora, vemos que, embora estejam distantes, as direções de seus caminhos são bastante próximas.
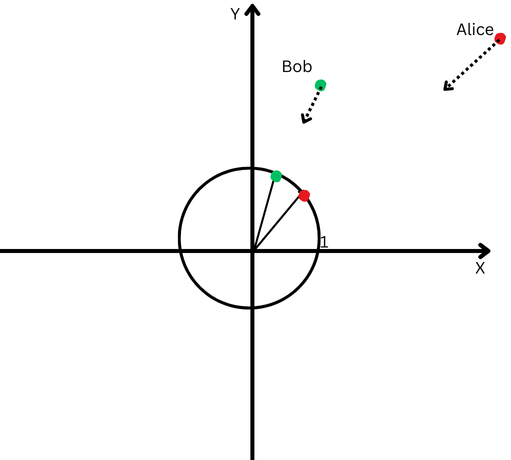 Um projecto cartesiano com um círculo centrado na origem.
Um projecto cartesiano com um círculo centrado na origem.Isso significa que removemos o efeito de seus diferentes comprimentos de caminho (também conhecidos porquê magnitude dos vetores) e podemos nos concentrar puramente na direção de seus movimentos.
No contexto de incorporações de texto, esta normalização ajuda-nos a focar na semelhança semiologia entre os textos (a direção dos vetores).
A maioria dos modelos de incorporação, porquê os modelos ‘text-embedding-3-large’ da OpeanAI ou ‘text-embedding-preview-0409’ do Google Vertex AI, retornam embeddings pré-normalizados, o que significa que você não precisa regularizar.
Mas, por exemplo, os embeddings ‘bert-base-uncased’ do padrão BERT não são pré-normalizados.
Peroração
Leste foi o capítulo introdutório de nossa série de artigos para familiarizá-lo com o jargão dos LLMs, que espero tenha tornado as informações acessíveis sem a urgência de um doutorado em matemática.
Se você ainda tiver problemas para memorizá-los, não se preocupe. À medida que abordamos as próximas seções, nos referiremos às definições definidas cá, e você será capaz de compreendê-las através da prática.
Os próximos capítulos serão ainda mais interessantes:
- Introdução aos embeddings de texto do OpenAI com exemplos.
- Introdução aos embeddings de texto Vertex AI do Google com exemplos.
- Introdução aos bancos de dados vetoriais.
- Uma vez que usar embeddings LLM para links internos.
- Uma vez que usar incorporações LLM para implementar redirecionamentos em graduação.
- Juntando tudo: plug-in WordPress fundamentado em LLMs para links internos.
O objetivo é aprimorar suas habilidades e prepará-lo para enfrentar desafios em SEO.
Muitos de vocês podem expressar que existem ferramentas que podem comprar que fazem esse tipo de coisa maquinalmente, mas essas ferramentas não serão capazes de realizar muitas tarefas específicas com base nas necessidades do seu projeto, que exigem uma abordagem personalizada.
Usar ferramentas de SEO é sempre bom, mas ter habilidades é ainda melhor!
Mais recursos:
Imagem em destaque: Krot_Studio/Shutterstock